

Questions I use to assess datasets:
How hard is it to gather this data?
Think of the difficulty to access
To store
To generate
Is this data set difficult to copy? Could you have come to the same conclusion with a different dataset?
Dimensionality: How many different points can you correlate. Basically how many different variables are measured.
How representative is it of the population you want to know more about? Some call this “The breath of the data”.
Perishability; How long will this data be useful?
There is an interesting post from the MAN Group, an investment management firm (and also the sponsor of the “Man Brooker Book Prize”. About how data today is different then it was in the past, and what you should be mindful of when buying. Here I’ll provide you with what I considered to be interesting:
Quick overview of how the types of datasets have exploded:
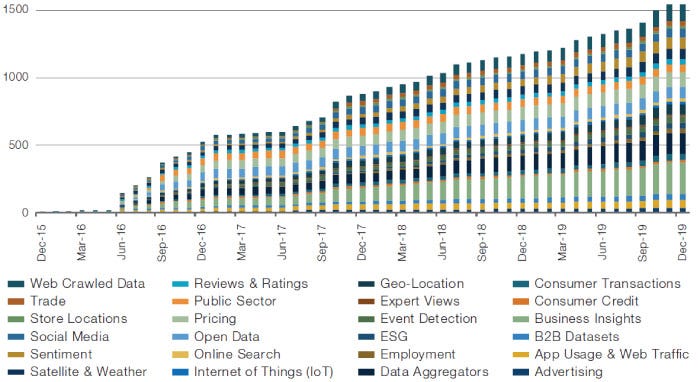
The graph above broke down the type of data by category.
Man points out you would also want to break that down by who generates the data:
Individuals; social media, consumer transactions, reviews, ratings, online search;
sensors: satellites
Businesses: store locations, business insights
and I will add Governments, this can be from the federal all the way to the town level.
How far back does this data go?
It looks like 63% of the data is at least 5 years old.

This is pretty nice but depends on the use case.
You do not necessarily want data to go back decades. One thing I learned is that you should really distinguish between perishable and non-perishable data.
A quick example for perishable data: The usefulness of transactional Information is limited in time. You don’t necessarily want to know what people bought 20 years ago. To predict what they would buy now. Hence, in this case, I would call it perishable data.
An example of non-perishable data, this is data that doesn’t change quickly over time. Examples are locations, family composition, contact details
When you model thing you will base yourself on past data. And one thing you always want to avoid is overfitting the data. I’ll tell you with perishable data you have to be extra careful not to overfit the data.
Most expensive Data types:

I was surprised this list doesn’t include health data. I would assume it would rank in the top 3. Since there are heavy privacy laws protecting it, it is hard to get and usually hard to measure.
I was also surprised credit data is so expensive. 🤷♂️
Overall a surprising list.
A bit further I read an example of a use case:
Pharmaceutical pipeline from clinical research transitions: Using data derived from multiple sources, including clinical patents and regulatory history of drugs, to provide a likelihood-of-success metric;
Let me save you time and money on this one: I highly doubt these variables will give you a reliable “ likelihood-of-success metric”.
If you want to know more I would advise you to read their piece.